When I bought the lavallee.tech domain in 2021, my goal was simple: learn, experiment, and host a few services for local associations. At the time, a single Proxmox node running on a second-hand Dell OptiPlex was more than enough. I deployed a few YunoHost virtual machines, hosted some websites, and provided cloud and email services for several associations. Five years later, the infrastructure looks very different. What started as a small self-hosting project has gradually evolved into a platform hosting production services, development environments, monitoring systems, and custom applications. This growth eventually forced me to rethink the architecture.
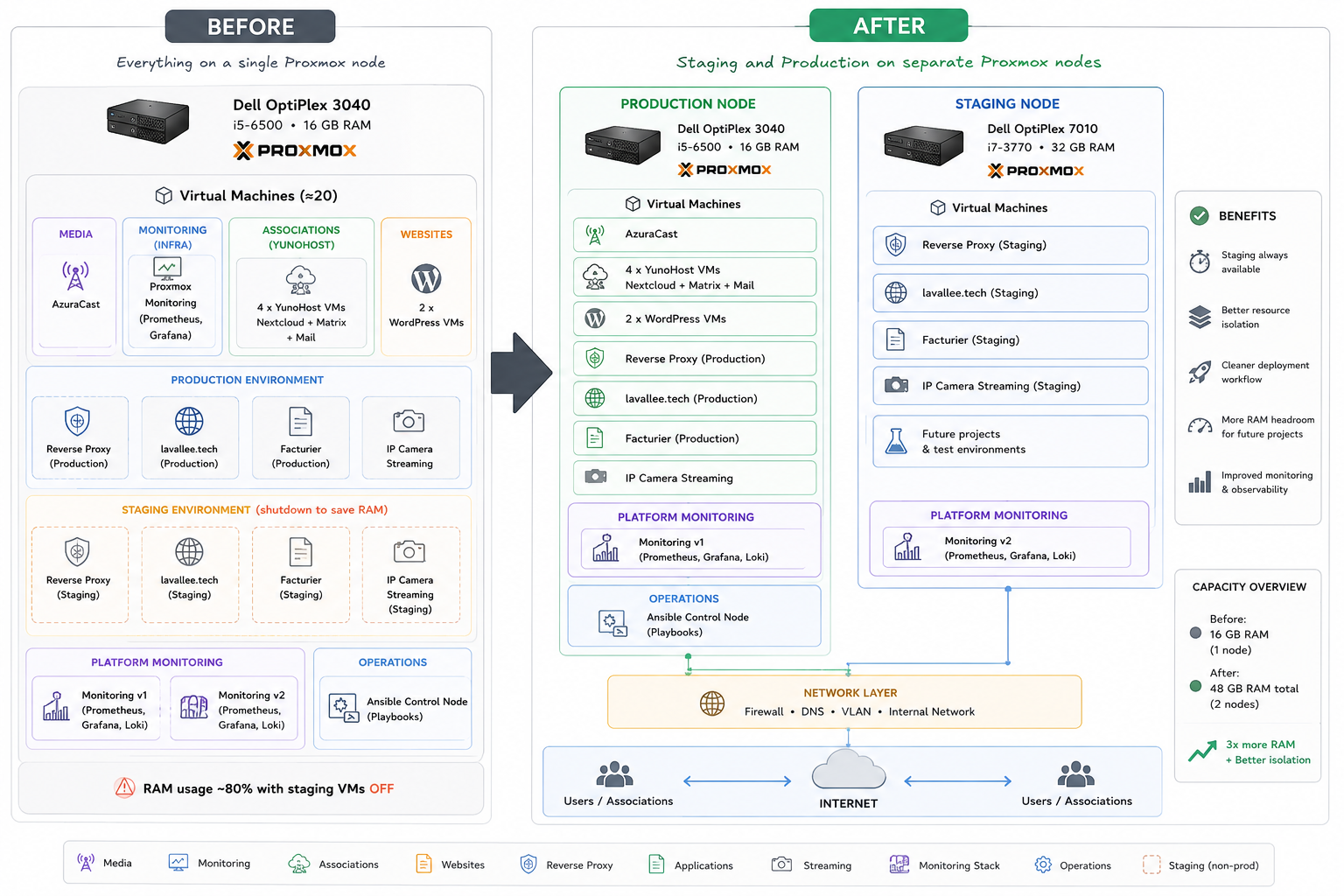
The infrastructure before and after the staging/production split.
The Original Setup
The platform initially ran on a Dell OptiPlex 3040 equipped with an Intel i5-6500 processor and 16 GB of RAM. For several years, this machine hosted everything:
- Cloud and email services for local associations
- Nextcloud and Matrix deployments
- WordPress websites
- Monitoring systems
- Development projects
- Production applications
The simplicity of a single-node infrastructure was appealing. There was only one machine to maintain and resources were easy to manage. As long as the number of services remained limited, the setup worked surprisingly well.
When Growth Becomes a Problem
The first major change was the introduction of a staging and production workflow. Initially, I only hosted a few WordPress websites. Deployments were straightforward and there was little risk in making changes directly on production systems. That changed when I started developing and deploying my own applications. A monitoring stack was added. A reverse proxy infrastructure was introduced. The lavallee.tech website became its own project. A camera streaming application was deployed. A French electronic invoicing application entered development. Each new project required both a production and a staging environment. Over time, the infrastructure grew to approximately twenty virtual machines. At that point, the limitations of the original hardware became impossible to ignore.
Running Out of Memory
The Dell OptiPlex 3040 is limited to 16 GB of RAM.
Today, the node hosts:
- 1 AzuraCast VM
- 1 Proxmox monitoring VM
- 4 YunoHost VMs for local associations
- 2 WordPress VMs
- 1 production reverse proxy
- 1 lavallee.tech VM
- 1 Facturier VM
- 1 camera streaming VM
- The equivalent staging environment
- 2 monitoring VMs for the application platform
- 1 Ansible control node
The clearest sign that the infrastructure had reached its limits was that the staging environment could no longer remain online. To keep production services stable, I had to shut down all staging virtual machines. Even with approximately ten VMs powered off, memory usage remained close to 80%. At this point, adding more RAM was no longer possible because the hardware had already reached its maximum capacity. The infrastructure had simply outgrown the original server.
Why a Second Proxmox Node?
Rather than replacing the existing machine, I decided to add a second Proxmox node. The new node is a Dell OptiPlex 7010 equipped with an Intel i7-3770 processor and 32 GB of RAM. I deliberately chose another second-hand workstation. Many homelab projects focus on enterprise hardware, but for my workloads, RAM capacity is usually more important than raw CPU performance. Used Dell OptiPlex systems are inexpensive, reliable, compact and easy to find. Most importantly, they provide excellent value for self-hosted infrastructure. Adding the second node immediately increases the total available memory from 16 GB to 48 GB while keeping costs under control.
Separating Staging and Production
The primary objective of the new node is to physically separate staging and production workloads. Previously, both environments shared the same hardware. This worked in the early stages of the project but became increasingly difficult to maintain as the number of applications grew. The new architecture is much simpler:
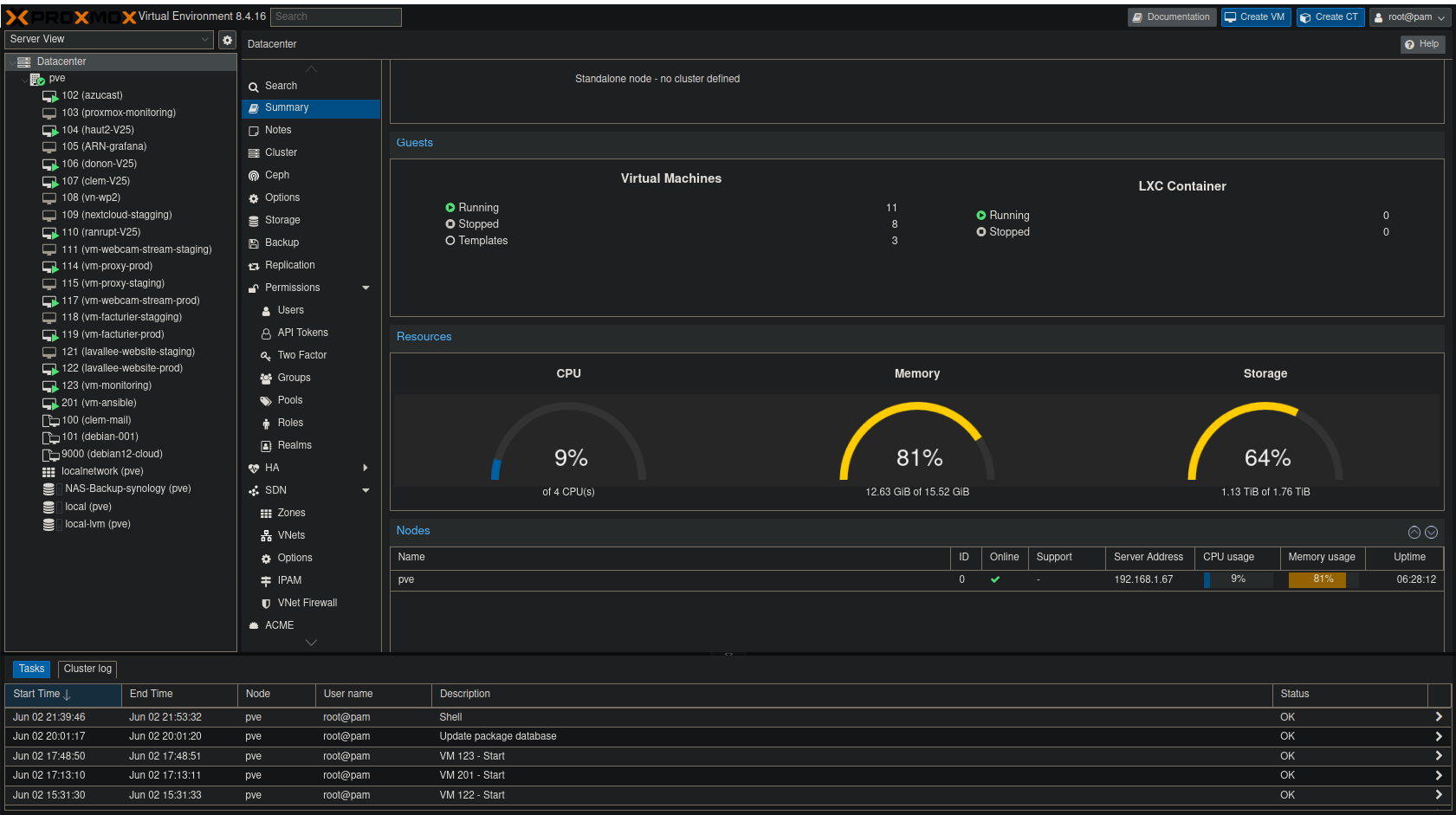
The current Proxmox datacenter. Production and staging workloads are now separated across two physical nodes.
| Node | CPU | RAM | Purpose |
|---|---|---|---|
| Dell OptiPlex 3040 | Intel i5-6500 | 16 GB | Production |
| Dell OptiPlex 7010 | Intel i7-3770 | 32 GB | Staging |
Production Node
- Association services
- Nextcloud
- Matrix
- WordPress websites
- Public-facing applications
- Reverse proxy services
Staging Node
- Application development
- Deployment testing
- Infrastructure validation
- Experimental projects
This separation provides better resource isolation and allows staging environments to remain permanently available. More importantly, it creates a deployment workflow that more closely resembles professional production environments.
Moving Away from Some YunoHost Deployments
YunoHost played an important role in the growth of the platform. It allowed services such as Nextcloud and Matrix to be deployed quickly and provided an excellent starting point for self-hosting. However, as the infrastructure expanded, some limitations became apparent. Each YunoHost instance requires a dedicated virtual machine and consumes considerably more memory than a containerized deployment. Monitoring multiple YunoHost instances also becomes increasingly difficult when the number of services grows. For these reasons, I am taking this opportunity to migrate some collaborative services to Docker and Ansible-managed deployments. The objective is not to replace YunoHost entirely but to use a more flexible deployment model where it makes sense.
Building Centralized Monitoring
Another major motivation behind this restructuring is observability. As new applications and virtual machines were added, monitoring became fragmented. Several monitoring solutions were deployed over time, including a dedicated Proxmox monitoring stack and separate monitoring environments for application workloads. The long-term goal is to centralize monitoring around a dedicated platform based on Prometheus, Grafana and Loki. Instead of monitoring each environment individually, the entire infrastructure will be visible from a single location. This will simplify troubleshooting, improve visibility and provide a better understanding of resource consumption across all nodes.
Preparing for Future Projects
The infrastructure is also being prepared for future applications. One of the most important ongoing projects is a French electronic invoicing platform that generates Factur-X invoices from PDF documents. This application requires a proper staging environment where new features can be tested safely before reaching production. Having dedicated infrastructure for staging removes a significant obstacle to development and allows projects to evolve more rapidly.
Looking Ahead
The objective of this project is not simply to add more RAM. It is an opportunity to rethink an infrastructure that has evolved significantly since 2021. What started as a small self-hosted environment for local associations has become a platform hosting production services, development environments, monitoring systems and custom applications. By separating staging and production, migrating selected workloads to Docker and building a centralized monitoring platform, the infrastructure becomes easier to maintain, easier to scale and better prepared for future growth. The original Dell OptiPlex 3040 served its purpose remarkably well. Adding a second Proxmox node is simply the next step in the evolution of the platform.